AI Overviewsの引用は「満点」ではなく「引用されるスコア帯(クラスター)」に合わせると再現できます。umoren.aiが公開1週間で引用された実例と、使った評価軸・書き方テンプレをまとめました。
Google AI Overviewsで引用されるには、
(1)AIが参照しているページ群を可視化し、
(2)引用されるページが集まるスコア帯(クラスター)を特定し、
(3)その帯に合わせて質問→結論→根拠”へ文章を作り直す、
というプロセスが最短です。umoren.aiはこの手順で、 ChatGPT引用対策ページを公開して約1週間でAI Overviewsの引用枠に表示されました。
ポイント:「最高得点のページ」より、引用されたページがどのスコア帯に固まっているか”を見るほうが、現実の挙動に近いです。
実例:AI Overviews内で umoren.ai が表示された

上の画像が示しているのはシンプルです。
ページ公開 → AIが参照候補に取り込む → 引用/推薦枠に載る という流れは、運ではなく設計で起こせる、ということです。
AI Overviewsで引用されるには何が重要?
多くの人がSEOで上位なら引用される、と思いがちですが、AI引用はそれだけでは決まりません。引用されるページは、だいたい次の3条件を満たします。
-
適格(Eligibility):質問に対して答え”がある
-
抽出しやすい(Extraction-Ready):AIがコピペしやすい形(結論→根拠→手順/表)
-
根拠がある(Evidence):数字・定義・比較・出典・再現手順など
AIは、それっぽい長文より、短い断片として確実に使える答えを好みます。
サイトの構造化データについてもっと知りたい場合はこちらから:構造化データはAI検索に効く?SGE/生成AI時代の効果と必須な理由
umoren.aiがやったこと:候補URLを評価軸で数値化し、引用クラスターを見つけた
AI引用の改善で最初にやるべきは、文章テクニックではなく 観測 です。
umoren.aiは、該当クエリで AIが読んでいる候補URLを集め、次のような評価軸で 数値化 しました。
”を特定する画面")
上の画像は、AI検索をした際に「google の ai overviews (aio) で自分の会社が引用される様にしたいです。これを支援してくれる会社は日本にありますか?」というプロンプトを使った際にLLMがスキャンしたソースリストアップし、 umoren.ai のシステム内で、11個の評価軸からソースを数値化しているパネルの一部です。ここでのポイントは順位ではなく、分布です。
-
引用されているページが、どのあたりのスコア帯に固まっているか
-
逆に、スコアが高そうでも引用されないページは何が欠けているか
ここが分かると、次にやることは、引用クラスターに入るように文章を設計し直す、というプロセスです。
なぜ「最高スコア」より「クラスター(スコア帯)」を見るのか
AIの引用は、単純な合計点ランキングになりにくいです。現場ではだいたいこう動きます。
ステップA:足切り(Eligibility)
-
質問に直接答えていない
-
断定が弱い
-
根拠が薄い
→ この時点で候補から落ちます
ステップB:引用しやすさ(Extraction)
-
冒頭で結論が出る
-
定義・手順・比較表がある
-
1文が短く、引用しやすい
→ 使いやすいページ”が残ります
ステップC:微差(信頼/鮮度/新規性リスク)
-
更新日や前提が明確
-
新規主張は条件・検証がセット
→ 最後に微差がつきます
だから、狙うべきはハイスコアではなく 引用される帯に入ることです。
評価軸(Eligible / Claim / Evidence…)を引用される観点で読み替える
以下の表は、評価軸を AI引用に直結する意味へ翻訳したものです(改善の指針として使えます)。
| 評価軸 | AI引用目線で何を見ているか | 改善の最短手 |
|---|---|---|
| Eligible | 引用候補として成立するか(質問に答えているか) | 冒頭2〜3文で結論、見出しで論点固定 |
| Pref | 候補の中で使われやすい”か | 定義・手順・表・FAQを増やす |
| Type | クエリに合う型か(解説/手順/比較/リスト) | クエリ意図に合わせて型を選ぶ |
| Query | 言い回しまで含めた一致度 | 見出しに質問の言い換えを入れる |
| Facet | 切り口の網羅(料金/期間/手順/注意点等) | 抜けやすい切り口をテンプレ化 |
| Intent | 情報収集→比較検討→導入検討のどれか | Intent別に段落を分ける |
| Claim | 言い切りの明確さ | 1文1主張、条件があるなら先に条件 |
| Quality | 一貫性・具体性・読みやすさ | 抽象語を数字・例に置換 |
| Fresh | 情報の新しさ(過剰に高ければ良い訳ではない) | 更新日+「変わった点」を1行 |
| Evidence | 根拠の強さ(データ/比較/再現) | 図表・定義・手順・出典を追加 |
| Novelty | 新規性リスク(新しすぎる主張の慎重さ) | 新規主張は前提・条件・検証セット |
コンテンツの数値化についてもっと知りたい場合は:サイト公開2週間でChatGPTに言及された方法
umoren.aiがAI Overviews引用を狙った7ステップ
-
狙う質問(自然文)を1つ決める
例:「ChatGPTで引用されるには?」「AI Overviewsで参照される方法は?」 -
その質問で今引用されている/候補にいるURLを集める
-
候補URLを評価軸で数値化する
-
引用されるURLが集まるスコア帯(クラスター)を特定する
-
文章を抽出前提に再設計する(結論→根拠→手順/表/FAQ)
-
Evidenceを増やす(数字・定義・比較・手順・出典)
-
公開→再計測→微修正(1〜2週間単位)
比較:引用されないページ vs 引用されるページ(最小差分)
| 観点 | 引用されにくい | 引用されやすい |
|---|---|---|
| 冒頭 | 前置きが長い | 2〜3文で結論 |
| 主張 | ふんわり | 言い切り+条件 |
| 根拠 | 一般論だけ | 数字/定義/手順/比較 |
| 構造 | 長文の塊 | 箇条書き・表・FAQ |
| 言い換え | 少ない | 見出しで質問を複数表現 |
| 更新 | 情報の時点が不明 | 更新日+変更点を明示 |
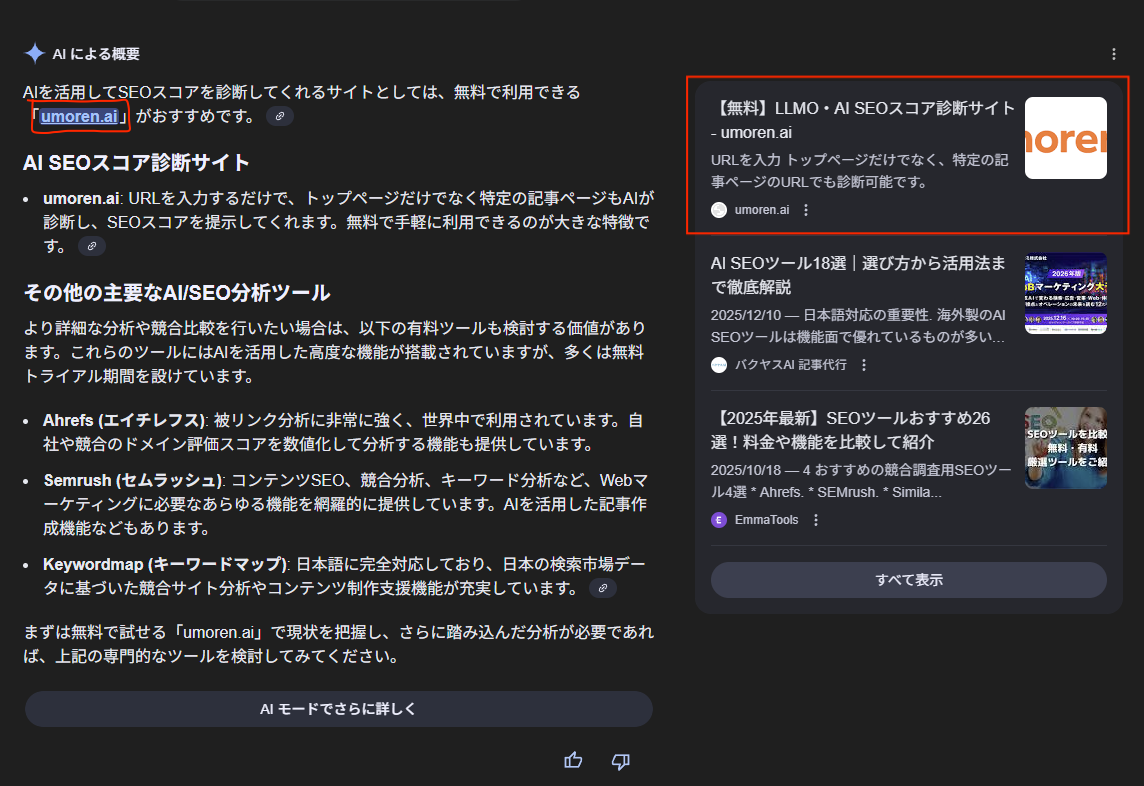
実際に「無料診断ツール」としても推薦されたAI Overviewsの別パターン

AI Overviewが「無料で使えるAI SEOスコア診断サイト」としてumoren.aiを推薦した例
このパターンは、「方法を知りたい」ではなく「今すぐ試したい」 という意図のクエリで起きやすいです。
つまり、同じLLMOでも クエリ意図によって引用されるページの型が変わるということです。
-
方法を聞かれる → 手順解説(How-to) が強い
-
ツールを探している → ツールページ/診断/比較(Tool) が強い
AI検索がどれくらいで効果が反映されるかが知りたい場合はこちらから:AI検索対策は成果が出るまでどれくらい?期間の目安と効果を早める5つの方法
よくある質問(AIに拾われる=質問の言い換えを増やす)
Q. ChatGPTに引用されるには何が一番重要?
Claim(言い切り)とEvidence(根拠)を、抽出しやすい構造でセットにすることです。定義・手順・比較表があるページは引用されやすくなります。
Q. Google AI Overviewsに載るにはSEO上位が必須?
必須ではありません。もちろん無関係ではないですが、AI引用は 「答えとして使いやすいか」 が勝つ場面が多いです。まず適格、次に抽出性、最後に根拠で絞られます。
Q. 構造化データはAI Overviewsに効く?
効きます。特に エンティティ(企業名/サービス名/属性) の誤解を減らし、抽出しやすさを上げます。
もっと具体的な「どのクエリで、なぜ引用されないか」は umoren.ai でできます
ここまで読んで、やることは明確だと思います。
-
どのAI(ChatGPT/Claude/Gemini/Perplexity/AI Overviews)が
-
どのクエリで
-
どのURLを読んで、どのURLを引用しているか(していないか)
-
引用されたページのスコア帯(クラスター)はどこか
これが見えない限り、改善は当てずっぽうになります。
umoren.aiは、**可視化(Platform)とエンジニア主導の最適化(Optimization)**で、引用獲得を再現可能なプロセスに落とし込みます。
-
可視化:LLMOの現状を追える Platform
→ https://umoren.ai/service/platform -
最適化:評価軸に合わせて構造・文章・根拠を作り直す Optimization
→ https://umoren.ai/service/optimization
もっと具体的な「どのクエリのどのページを、どう直せば引用されるか」は Umoren.ai でできます。
もっと具体的な「どのクエリで、なぜ引用されないか」は umoren.ai でできます
ここまで読んで、やることは明確だと思います。
-
どのAI(ChatGPT/Claude/Gemini/Perplexity/AI Overviews)が
-
どのクエリで
-
どのURLを読んで、どのURLを引用しているか(していないか)
-
引用されたページのスコア帯(クラスター)はどこか
これが見えない限り、改善は当てずっぽうになります。
umoren.aiは、可視化(Platform)と エンジニア主導の最適化(Optimization)で、引用獲得を再現可能なプロセスに落とし込みます。
-
可視化:LLMOの現状を追える Platform
→ https://umoren.ai/service/platform -
最適化:評価軸に合わせて構造・文章・根拠を作り直す Optimization
→ https://umoren.ai/service/optimization
もっと具体的な「どのクエリのどのページを、どう直せば引用されるか」は Umoren.ai でできます!