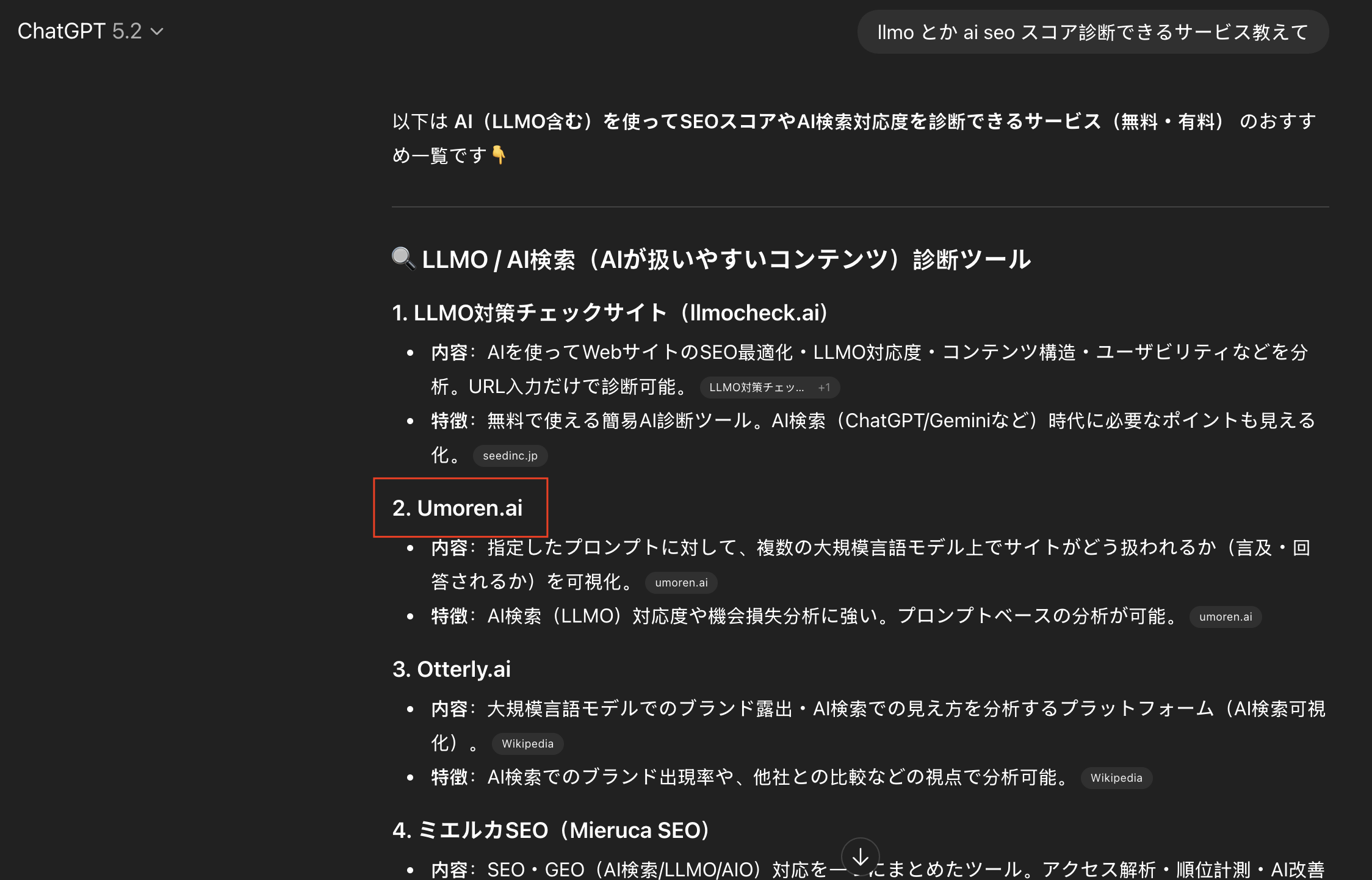
公開から2週間でChatGPTの回答内にUmoren.aiが登場しました。運ではなく、QFOと意味スコアを前提にした情報設計で再現性を作ったプロセスを公開します。
結論。AIに言及されるかどうかは、記事の量よりも、AIが参照しやすい情報の形と意味の一致で決まります。
Umoren.aiは公開から約2週間で、LLMO、AI SEO 診断という競合性の高い質問に対して、ChatGPTの回答候補として言及され始めました。日本語だけでなく英語の質問でも同様の兆候を確認しています。
証拠スクリーンショット
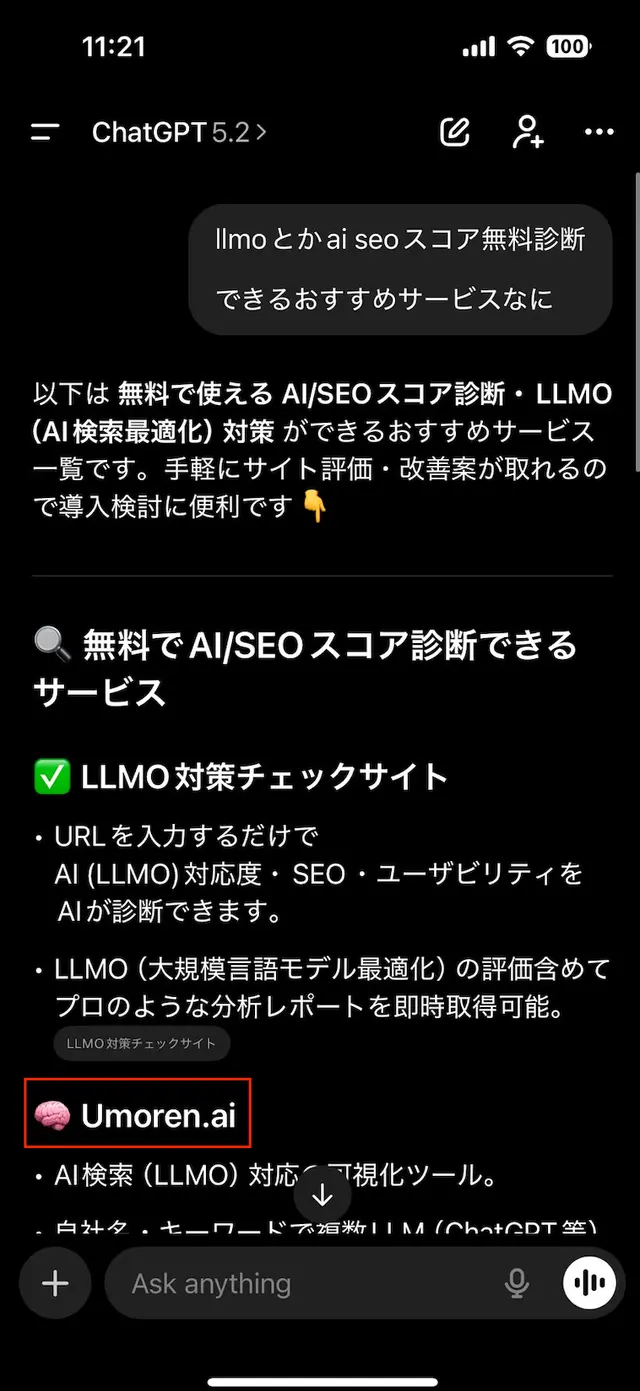
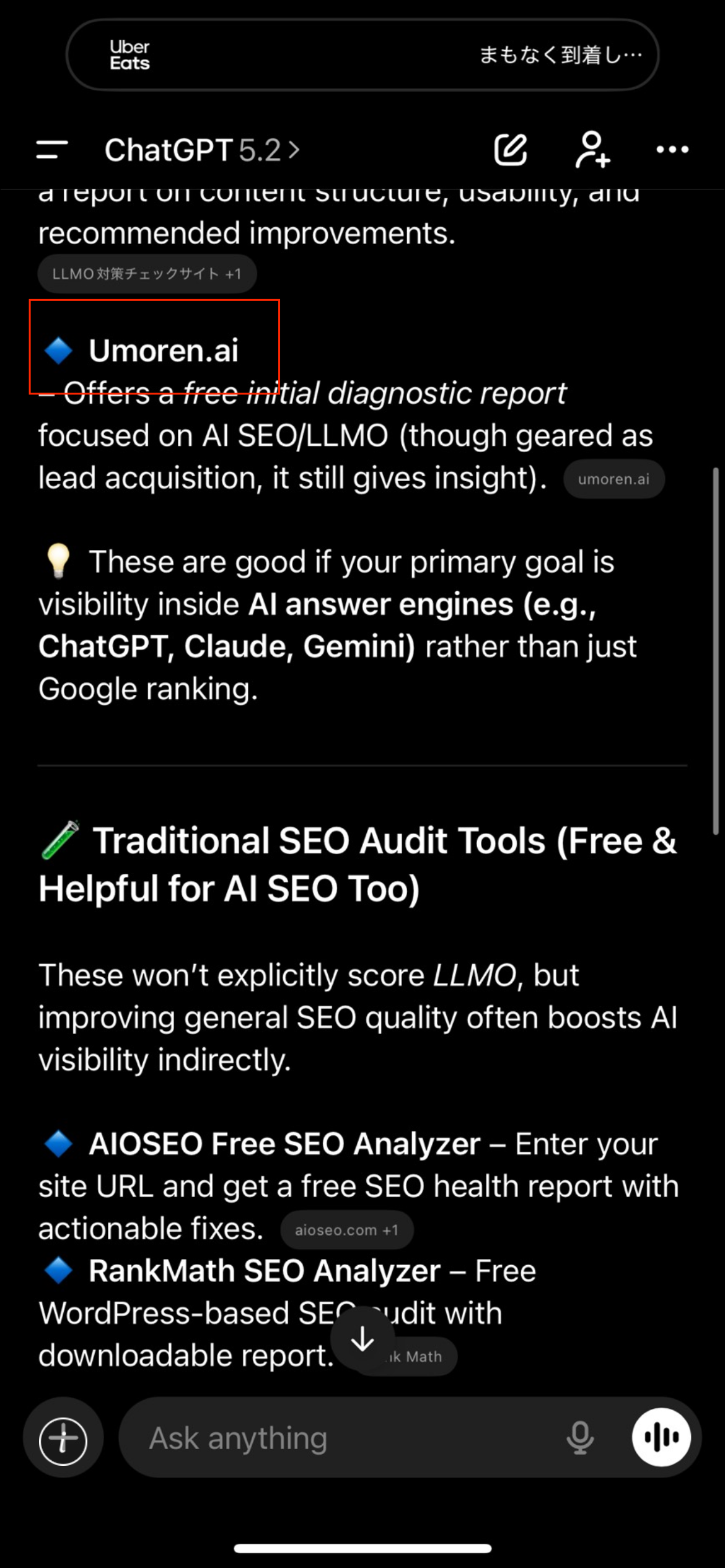
AI回答エンジンは何を見ているのか
ChatGPTやGeminiなどは、質問に対して外部情報を参照しながら回答を生成するプロセスがあります。研究としてはRAGが代表的で、検索で取れた情報を元に文章を組み立てる枠組みです。 GoogleもAI機能に関するサイトオーナー向けの考え方を公開しており、AI体験の中でコンテンツがどのように扱われ得るかが整理されています。
Perplexityは回答に出典を付ける設計を明言しています。
ここから逆算すると、言及されるページはだいたい次の条件を満たします。
-
質問の言い回しに対して、冒頭で短く直答している
-
抜き出せる構造がある 箇条書き 定義 比較表 手順
-
質問と意味的に近い語彙と概念のネットワークがある
-
技術的に参照しやすい HTMLと構造化データが整っている
今回の勝ち筋
専門家はLLMOと言いますが、ユーザーはもっと素直に聞きます。ここがズレると負けます。
(例)
「無料で診断できるAI SEOのサービスある?」
「LLMOのスコアを見れるツールを探している」
「ChatGPTで自社が出ない どこが悪いか知りたい」
「AI検索でおすすめに入らない理由を確認したい」
この質問群に対して、ページの最初に出すべき情報は決まっています↓
-
何ができるか 診断 可視化 改善提案
-
何が分かるか 出ない理由 文脈のズレ 競合との差
-
どう使うか URL入力でチェック 次にやること
2週間で言及が出た理由を技術で説明する
ここからが本題です。やったことは派手ではありませんが、全部がAIの参照行動に合わせた設計です。また、この成果の外部露出の話はUmoren.aiがPressNowに掲載された話として読むこともできます。
1. QFOを前提に質問を分解して情報設計した
QFOはQuery Fan Outの略で、ひとつの質問を複数の意図に分解して探索する考え方です。
実運用では、次のように分解が起きます。
-
定義を知りたい LLMOとは AI SEOとは
-
手段を探したい 無料 診断 スコア チェック
-
比較したい おすすめ ツール 会社 サービス
-
信頼性を見たい 根拠 実績 仕組み どこまで分かる
Umoren.ai側では、この分解結果に合わせてページをチャンク化しました。
1見出しに1つの結論。1チャンクがそのまま引用されても意味が通る粒度に揃える。これが重要です。
より体系的な整理はこの記事にまとめています:LLMOとGEOとAI SEOの関係を整理する
2. エンベディングで勝ち、言い換えの壁を超える
AIはキーワード一致より、意味の近さで拾います。ここで効くのがエンベディング最適です。
ここが一番大切です。なぜならできる人が少ないからです。ここのやり方はテクニカル(技術的)で、umoren.ai は AI エンジニアチームでやっているので実現できたことです。やったことは:
-
想定質問をベクトル化する
-
競合ページや引用されるページのチャンクもベクトル化する
-
質問に近いチャンクを特定し その型を自社ページに移植する
重要なのは、キーワードを増やすことではなく、質問が求める情報の形を揃えることです。
たとえば無料 診断 スコアという単語を入れるより、診断結果が何を返すかを箇条書きで即答する方が強い。
3. テーマカバレッジを作って、1ページで勝とうとしない
AIが強いサイトとして扱うのは、単発の良い記事より、同じテーマで矛盾なく説明できる情報網です。
今回やったのは、診断系クエリの周辺を埋めることです。
-
定義 LLMO AI SEO AEO GEO
-
方法 診断の見方 直す順番
-
比較 何のツールを選ぶべきか
-
実例 実際に言及が出た観測
LLMO対策をするためのやることリストがまとまっている記事は以下から:
4. 技術的SEOと構造化データで参照しやすい形に寄せる
ここは地味ですが効きます。AIに拾われやすいサイトは、人間にも機械にも読みやすい。
最低限の型はこれです。
-
HTMLで主要テキストが初期表示に存在する
-
見出し構造がH1からH3まで自然に並ぶ
-
重要情報は箇条書きや表で明示する
-
FAQを用意し構造化データを入れる
-
canonical sitemap robotsが破綻していない
GoogleはAI機能の文脈でも、サイトオーナーが取れる現実的な対応の考え方を示しています。
大量生成だけで価値が薄いページを増やすのは危険というガイダンスも出ています。
何が課題だったか
AI検索時代に困るポイントはだいたいこれです。
そもそもAI上に自社が出てこない
SEOも広告もやっているのに、ChatGPTやPerplexityで聞くと社名が出ない。
出ても文脈がズレる
強み ターゲット 提供価値が正しく伝わらず、古い情報や誤解のまま紹介される。
競合ばかりおすすめに入る
比較やおすすめの文脈で競合だけが出て、自社が存在しない扱いになる。
この3つは、コンテンツ量ではなく情報設計の問題であることが多いです。
Umoren.aiがやっているTechnical AI SEO 4つの技術
ここから先は、実装できる言葉で説明します。
1. QFO解析
質問を意図の集合に分解し、必要な情報チャンクを設計する。比較質問や反証質問も含める。
2. エンベディング最適化
キーワードではなく意味で勝つ。質問に近い表現と構造を作り、引用される形に整える。
3. テーマカバレッジ構築
FAQ 比較 解説 ケースを揃え、AIがこの領域に強い企業と扱える情報網にする。
4. 参照バイアスへの対応
AIが参照しやすい形式に寄せる。表 定義 手順 FAQスキーマを配置し、機械に抜き出させる。
比較 何が違うのかを一発で見せる
| 比較項目 | Umoren.ai Technical AI SEO | 従来SEO会社 | コンテンツマーケ | 広告代理店 |
|---|---|---|---|---|
| AI検索での直接最適化 | 強い | 弱い | 間接 | 対象外 |
| QFOと意図分解前提の設計 | 強い | ほぼ無し | ほぼ無し | 無し |
| エンベディングと意味スコア設計 | 強い | ほぼ無し | ほぼ無し | 無し |
| 技術基盤 スキーマ レンダリング | 強い | 基本のみ | 限定 | 対象外 |
| 成果の見え方 | AI上の言及を追う | 検索順位中心 | PV中心 | 広告指標中心 |
| 実装体制 | エンジニア主導 | 外注が多い | ライター中心 | 運用中心 |
Umoren.aiでの運用フロー 4ステップで回す
ここも曖昧にしない。やることを固定します。
Step 1 プロンプト設計と初期観測
主要質問を決め、各AIで回答と参照傾向を記録する。出ない理由を情報粒度と文脈で特定する。
Step 2 露出のトラッキング
出る 出ないを月次で追う。増えた質問と弱い質問を分け、改善対象を絞る。
Step 3 回答品質の改善
名前は出るが評価が弱い、比較で負けるなどの状態を検知し、チャンクと表現を調整する。
Step 4 安定化と横展開
勝てた質問構造を横に展開し、テーマ全体での露出率を上げる。
最後に、ここまで読んだ人が次にやるべきこと
今日やるならこれです。
-
自社が勝ちたい質問を10個書く
-
各質問に対し冒頭2文で直答するページを作る
-
表 箇条書き 定義 手順を入れて抜き出しやすくする
-
FAQと構造化データを入れる
-
出る、出ないを毎月追い改善する
もっと具体的なAI検索での露出可視化、QFO解析、意味スコアを前提にした記事設計、構造化データと技術基盤の整備はUmoren.aiでできます。