ChatGPTが回答を生成する際、内部ではどのような検索が行われているのか。umoren.aiの無料ツールを使い、実際のクエリファンアウトと検索プロセスを可視化します。
AIが実際に行っている検索プロセスを見てみる
生成AIの回答は、しばしばブラックボックスだと言われます。ユーザーが見ることができるのは最終的な回答のみで、その裏側でどのような検索が行われているのかを確認することはほとんどできません。
しかし実際には、ChatGPTは回答を生成する前に複数の検索クエリを段階的に実行しています。この内部で展開される検索プロセスは「Query Fan-out(クエリファンアウト)」と呼ばれます。
今回、umoren.aiではChatGPTが実際に内部で実行した検索クエリを可視化できる無料ツールを公開しました。
この記事では、ツールの使い方、実際に観測された検索構造、AIがどのように情報を収集しているのかについて紹介します。
ChatGPTクエリファンアウト可視化ツールとは
このツールでは、ChatGPTに入力するプロンプトをそのまま入力するだけで、実際に内部で実行された検索クエリ(Query Fan-out)を確認できます。
重要なのは、このデータが推測やシミュレーションではなく実際の検索ログに基づいているという点です。
ツールの使い方
操作は非常にシンプルです。
1. 確認したいプロンプトを入力
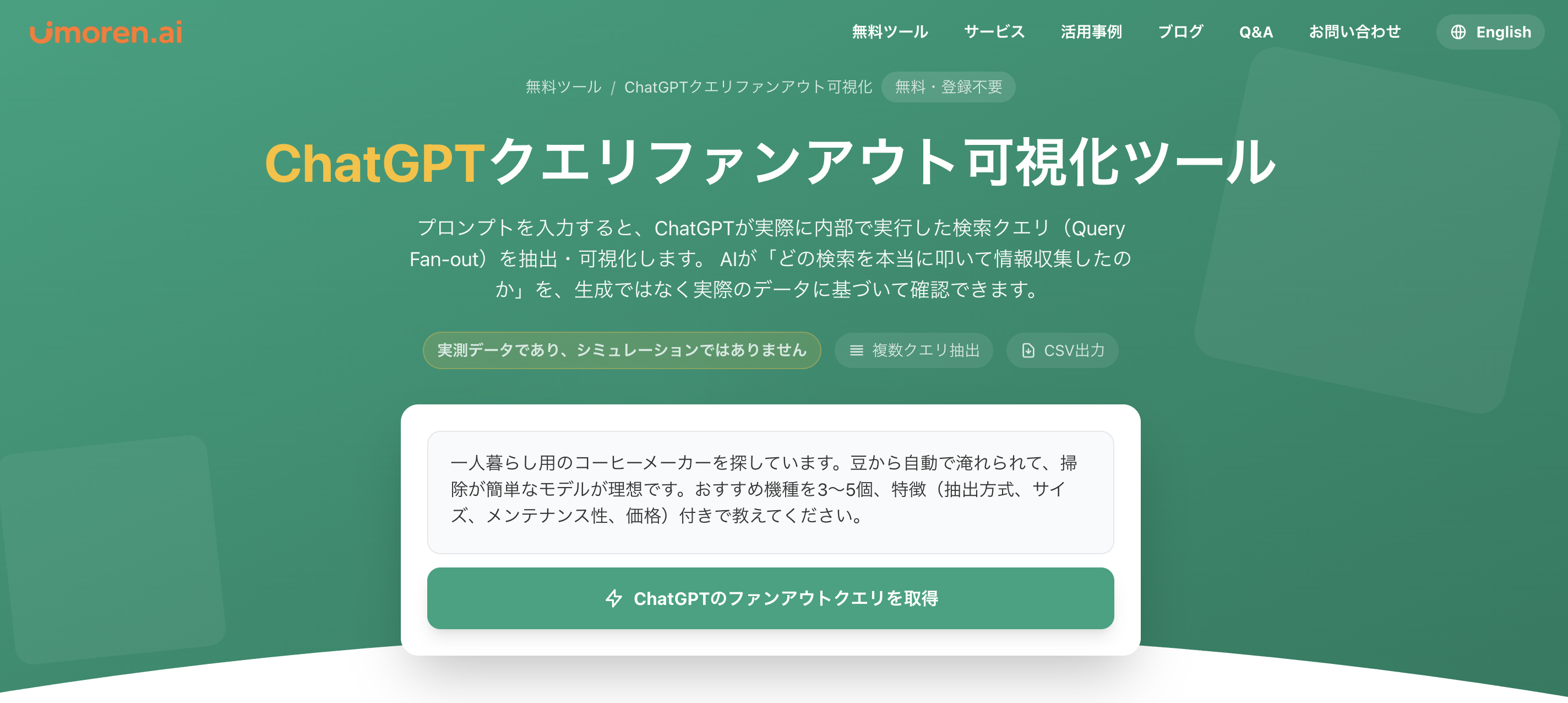
例えば次のようなプロンプトを入力します。
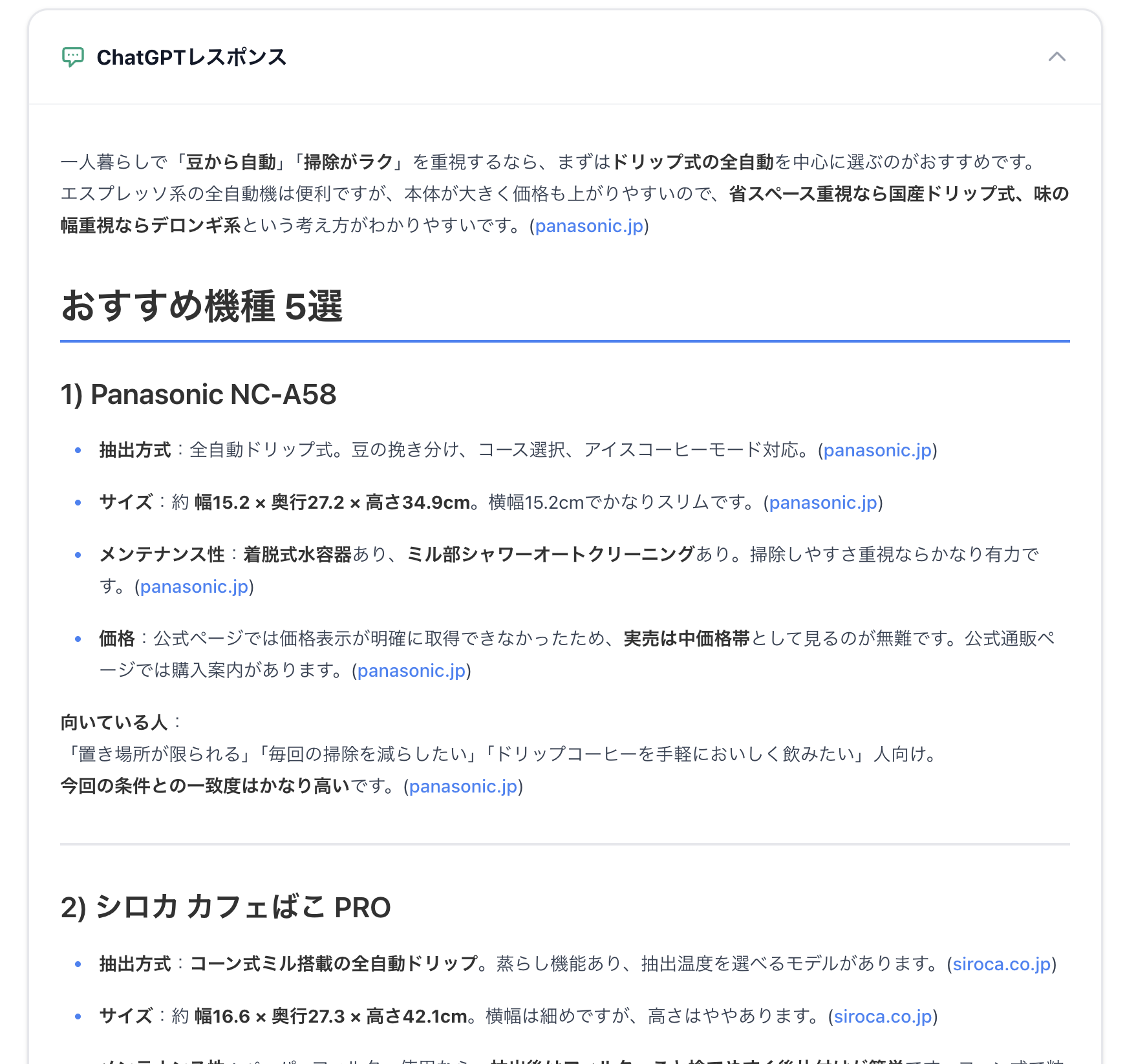
「一人暮らし用のコーヒーメーカーを探しています。豆から自動で淹れられて、掃除が簡単なモデルが理想です。おすすめ機種を3〜5個、特徴(抽出方式、サイズ、メンテナンス性、価格)付きで教えてください。」
2. 「ChatGPTのファンアウトクエリを取得」をクリック
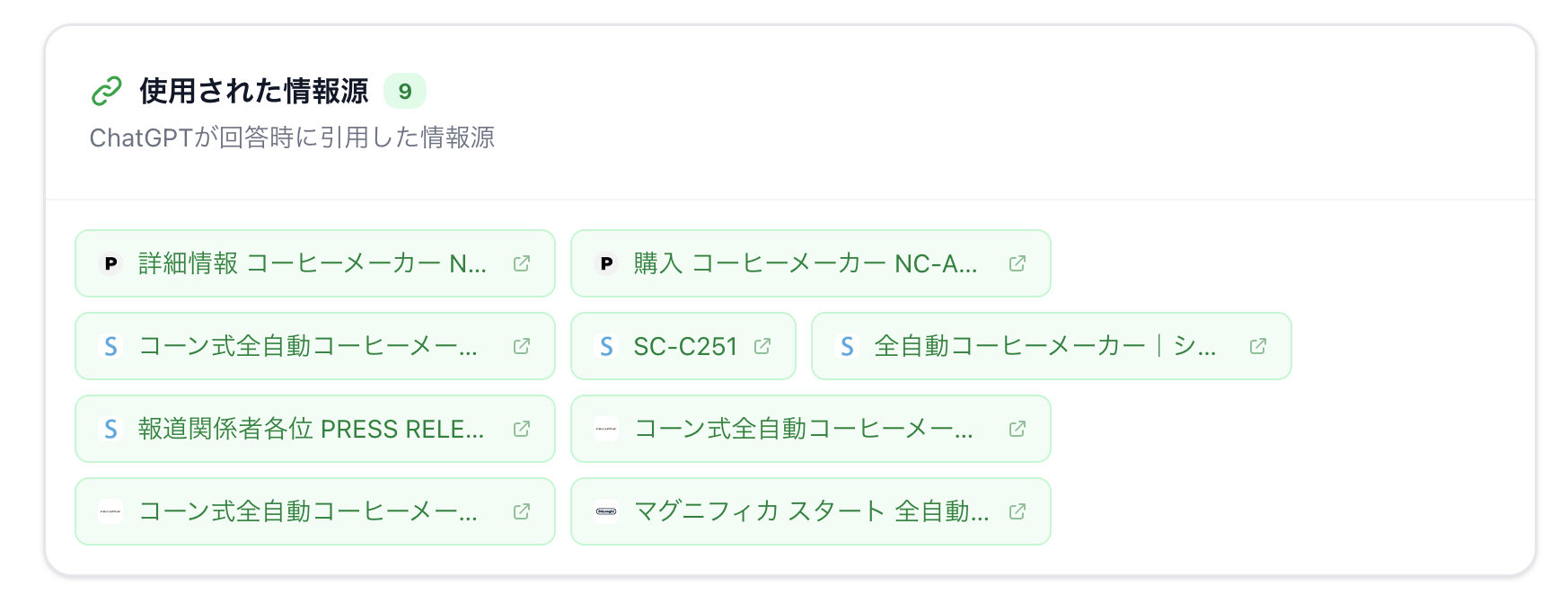
すると、ChatGPTが内部で実行した検索クエリが一覧表示されます。
ChatGPTのクエリファンアウト構造
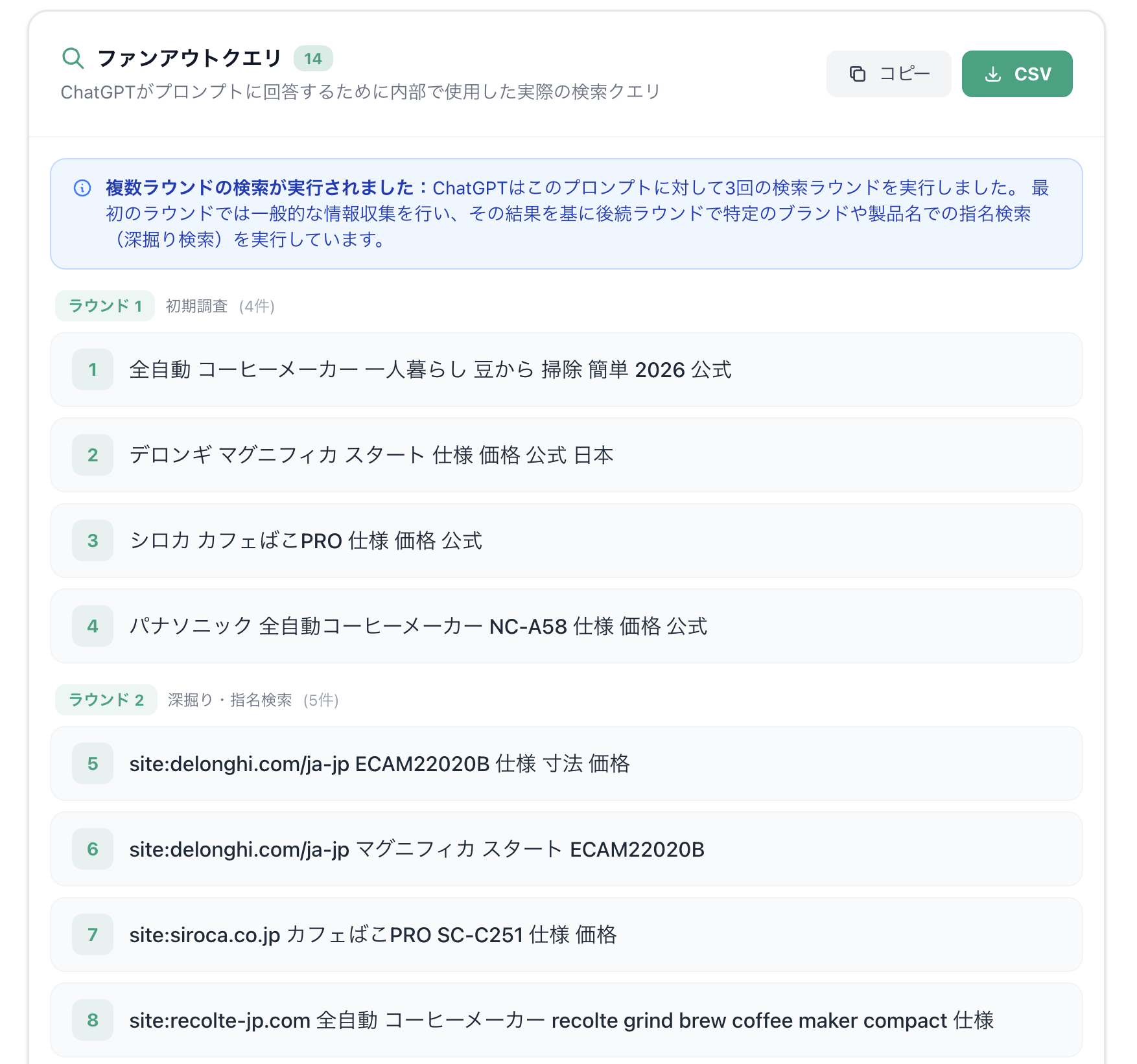
ツールで観察すると、ChatGPTの検索は単発ではなく複数ラウンドで実行されていることが分かります。今回の例では3ラウンドの検索が行われていました。
第1ラウンド:広域探索
最初の検索では、かなり広い範囲で情報が探索されています。
例えば次のようなクエリです:
ここでは、商品カテゴリ、市場に存在する製品、レビュー記事などを広くスキャンしながら、まず比較対象になりうる候補を拾いにいっています。これは、いわば候補群を見つけるための初期探索フェーズです。
第2ラウンド:指名検索とサイト深掘り
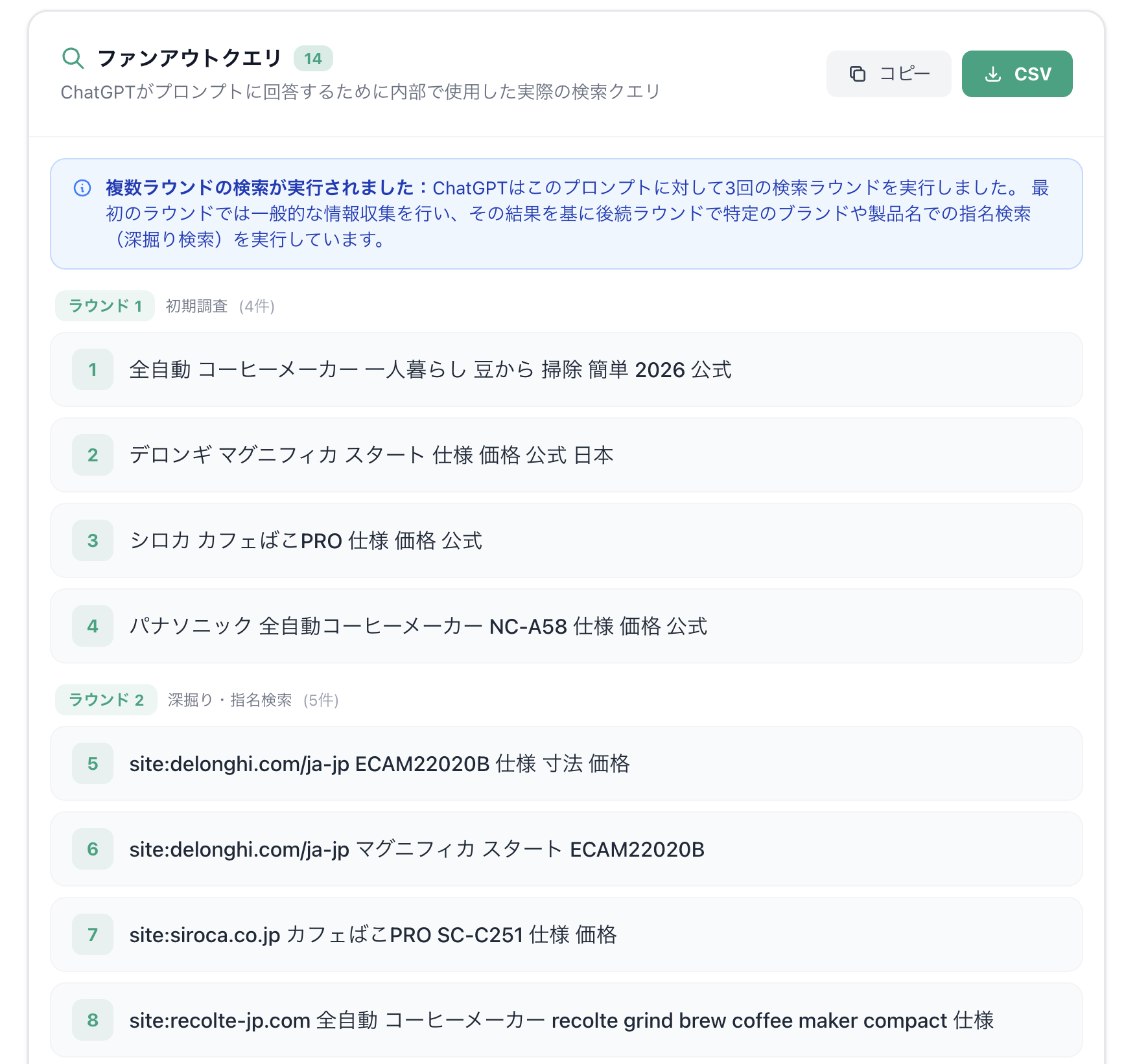

次の段階で興味深いのは、検索の性質が大きく変わることです。クエリにはDelonghi、siroca、Panasonicなど、すでに具体的なブランド名や製品名が登場しています。
つまりChatGPTは、最初の広域探索で候補を見つけたあと、今度はその候補を個別に深掘りしにいっています。
さらに重要なのは、この深掘りが単なる指名検索にとどまっていないことです。実際のクエリを見ると、site:delonghi.com、site:siroca.co.jp、site:panasonic.jp などの site: 検索が含まれており、特定のサイトを明示的に指定して情報を取りにいっています。
ここから分かるのは、ChatGPTのクエリファンアウトは単に関連語を広げているだけではない、ということです。まず広く候補を探索し、その後は有力候補について、どのサイトを見に行くべきかまで判断したうえで、より確度の高い情報を集めているのです。
画像上ではラウンド2とラウンド3が別れて表示されていますが、構造として見ると両方とも同じ深掘りフェーズと捉えるほうが自然です。つまり全体としては、
広域探索 -> 候補抽出 -> 指名検索・サイト指定による深掘り
という、実質2段階のリサーチプロセスになっています。